
By: Apurva Sinha, Senior Data Scientist, Walmart Global Tech
Walmart E-commerce platform is continuously growing and adding thousands of products every day to the site. Initiating the smooth transition of products to the site is a complex and evolving process. Successful shelving of products is crucial and depends on the correct and complete setup of product categorization. Proper shelving of the products mean products will have better search engine optimization (SEO) exposure and better overall product discoverability.
Problem Statement
Why do products not show up when searching on Walmart.com? Product discoverability is dependent on the correct assignment of shelves and the ranking of products. Walmart has internal rules based on the product hierarchy to perform the shelving of items. But assigning the correct product hierarchy is challenging. Products can have a default hierarchy and the default hierarchy can result in a product missing shelf and lower SEO exposure. In this blog, we will focus on assigning the correct product taxonomy hierarchy to improve product discoverability and SEO.
-Example of product taxonomy hierarchy-
Product Type: Action Figures & Product Family: Toys
Modeling Approach
In order to improve product discoverability, we will focus on finding the correct product hierarchy using state-of-the-art techniques. The problem is divided into 3 tasks:
- Identifying items with default taxonomy hierarchy.
- Preprocessing and Model building.
- Rules execution to assign shelf.
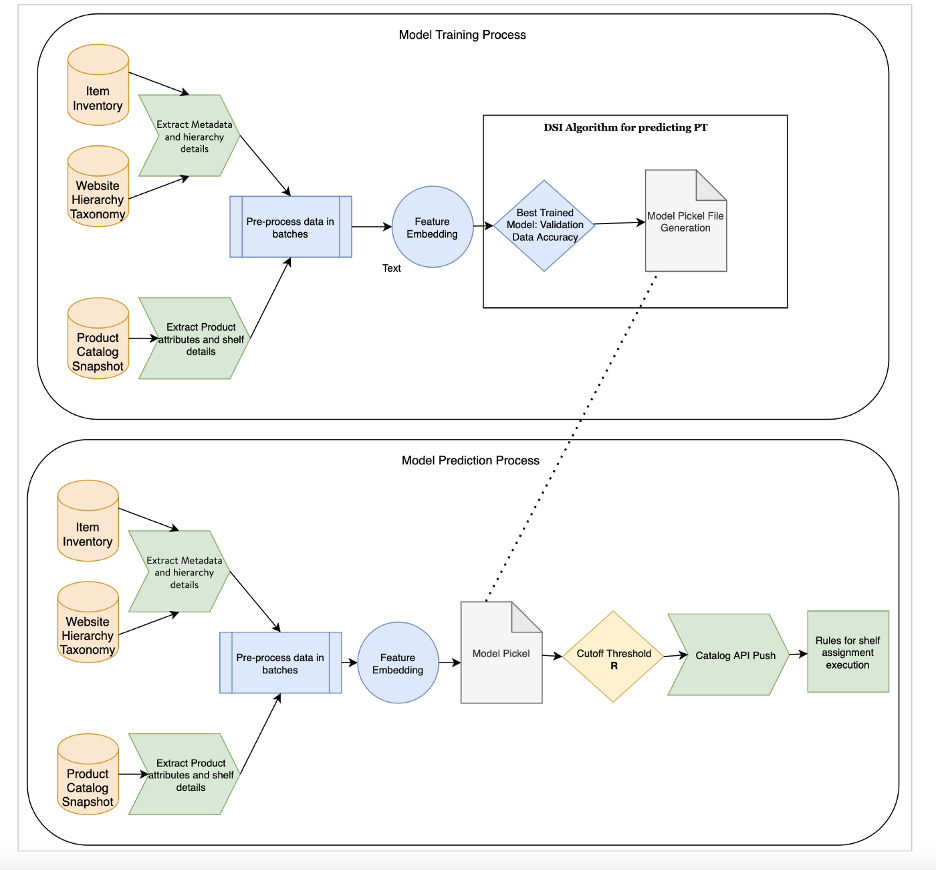
-Modeling Framework-
Sellers register the product on Walmart specifying the type of products being sold and current algorithms leverage that information to identify the reporting hierarchy. Combining this information, we focus on items with a default hierarchy.
For example, we focus on products that have default values for Product Category (PC), Product Family (PF), Product Type (PT) and UNNAV for missing shelf in the catalog data source.
Pre-Processing
We are approaching the problem at the department level. Each department has three levels of taxonomy: PC, PF and PT. The training sample is selected such that all levels are included. We are going to build a model which predicts PT for each default item and map the PF and PC based on the current taxonomy hierarchy mapping.
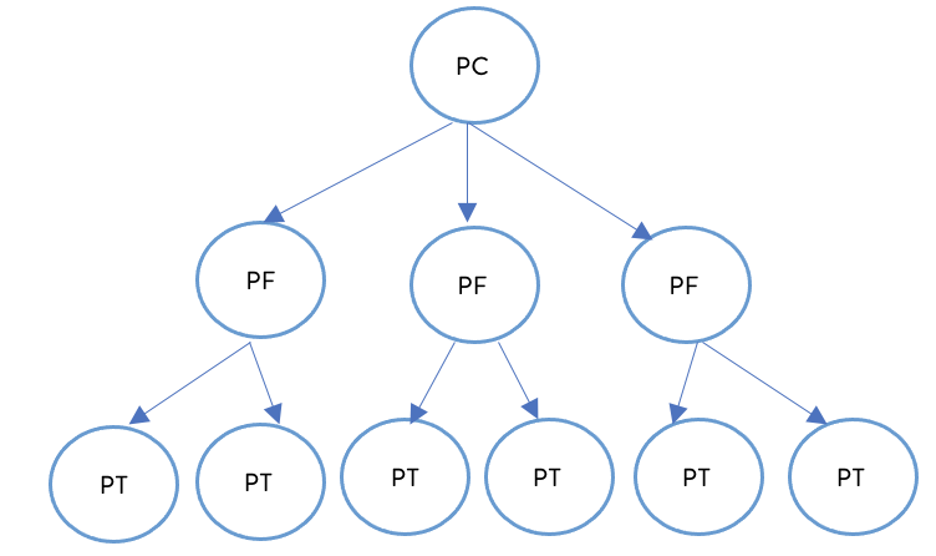
-Structure of Product Hierarchy Taxonomy-
Example: Toys department has one PC and eight PF and in total 200+ PT labels.
Items can belong to multiple departments: Example: Kids bicycle. This product can fall into Bikes under Toys as well as sports and Outdoor. In the current phase, assigning this product to either department works. But as future scope, a universal and scalable solution is in progress.
A training sample is created for each department to cover all PTs. We are utilizing product description and product name, remove unwanted special characters and emojis. These product attributes help the model to understand the PT of products.
Example of a product :

-Beginner Classical Ukulele Guitar Educational Musical Instrument Toys for Kids-
Product Name: Vithconl Beginner Classical Ukulele Guitar Educational Musical Instrument Toy for Kids, Brand: Vithconl
All the features are concatenated together and tokenized using Keras Tokenizer to create embeddings from the cleaned attributes to feed into the algorithm.
Example of sample data after pre-processing with multiple attributes:
Modeling
Hardware Requirement: GPU enabled server
The training data is divided into the stratified sample of train and validation dataset with a proportion of 70:30.
Multi-class classification models (CNN, Bi-LSTM, CNN-LSTM) are trained to assess the performance on validation data and finally, a CNN-LSTM model is selected based on the evaluation. A CNN-LSTM Model is trained for multiple epochs and early-stopping with min_delta to prevent overfitting. The weights of the model are saved using ModelCheckpoint of Keras to save_best_only.
Below is the sample architecture of the model.
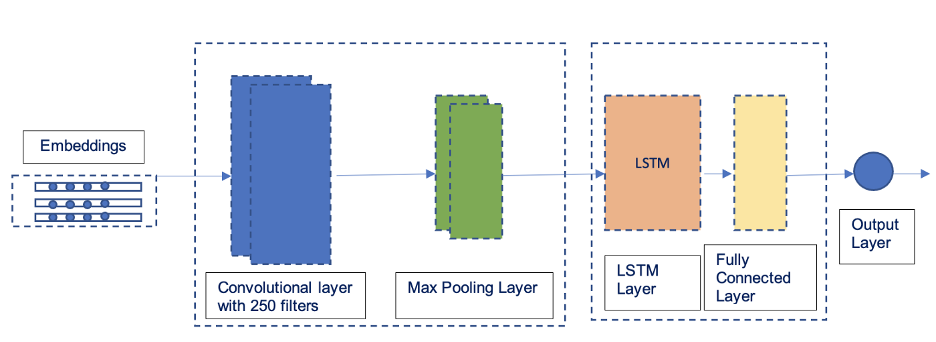
-CNN — LSTM-
The best-trained model weights are used to predict PT for the validation dataset. The accuracy of the model against validation data achieved is 88%. The cut-off threshold is finalized based on the accuracy within different quartiles of PT probability.
Prediction data is sampled from the default PT items with no shelf within each department. Prediction data is subdivided based on inventory stock. Data is cleaned, processed, and embedded into the trained saved model. The prediction file is generated based on the cutoff threshold with the newly assigned product taxonomy and pushed to catalog API. The shelf assignment rules execute based on pre-decided frequency to land products on the shelf with correct product attributes and hierarchy.
Strategy to subset 500 items for manual validation
500-subset products are selected from different probability thresholds above 80%. The predictions are manually validated for 500 products per department.
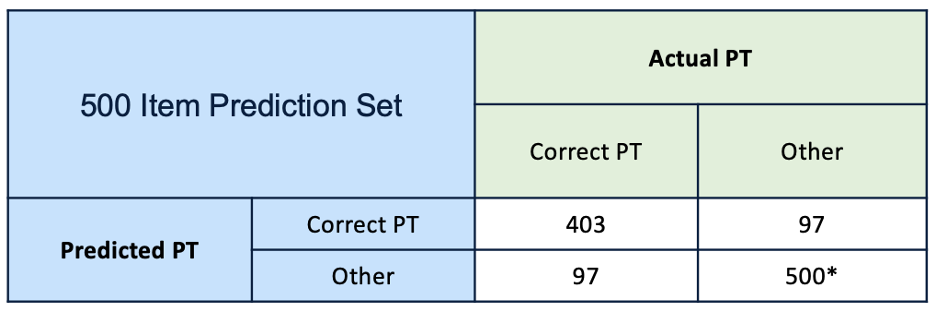
-Manual validation results-
For the toys department with 200+ PT labels, the accuracy of PT prediction for selected 500 products achieved is 80%.
Example:

-Beginner Classical Ukulele Guitar Educational Musical Instrument Toys for Kids-
The model predicts the PT as Toy Musical Instruments and the product is shelved under Kids Musical Instruments.
Conclusion
The above features and model is selected based on the accuracy of the model on validation data. The key objective is to extract important information from the product attributes and assign a product taxonomy hierarchy that rules can leverage to land a product on the shelf. We are piloting this approach for two departments and validating the product taxonomy hierarchy assigned.
Acknowledgment
This work is in progress between the eComm Ops Analytics, Catalog and Digital Strategy & Insights teams from Walmart Global Tech. Special thanks go to Srujana Kaddevarmuth
for this initiative, Abin Abraham for his contribution and support and eComm Ops Analytics’ Catalog team for helping throughout this effort.
Reference
Dimensional Sentiment Analysis Using a Regional CNN-LSTM Model.